
XPath-Tutorial in Selenium und anderen automatisierten Tools

 MIN
MIN
 01 Dez. 2023
01 Dez. 2023
In diesem xPath-Tutorial werden wir die Verwendung des XPath-Locators in Selenium WebDriver und anderen automatisierten Tools behandeln. In unserem Beitrag über die Suche nach WebElementen in Selenium haben wir die verschiedenen Arten von Locators untersucht, die in Selenium WebDriver verwendet werden.
Hier werden wir lernen, wie man Xpath-Locators erstellt, die verschiedenen Arten von Xpath, und wie man mit XPath nach dynamischen Elementen sucht.
Inhaltsübersicht
Was ist XPath?
XPath kann als eine Abfragesprache definiert werden, mit der man in XML-Dokumenten navigieren kann, um verschiedene Elemente zu finden. Die grundlegende Syntax des XPath-Ausdrucks lautet.
//tag[@attributeName=’attributeValues‘]
Lassen Sie uns nun ein Beispiel verwenden, um die verschiedenen Elemente der Xpath-Ausdrucksyntax zu verstehen – Tags, Attribute und Attributwerte. Betrachten Sie das folgende Bild einer Google-Webseite mit Firebug, das das Suchleisten-Div kontrolliert.
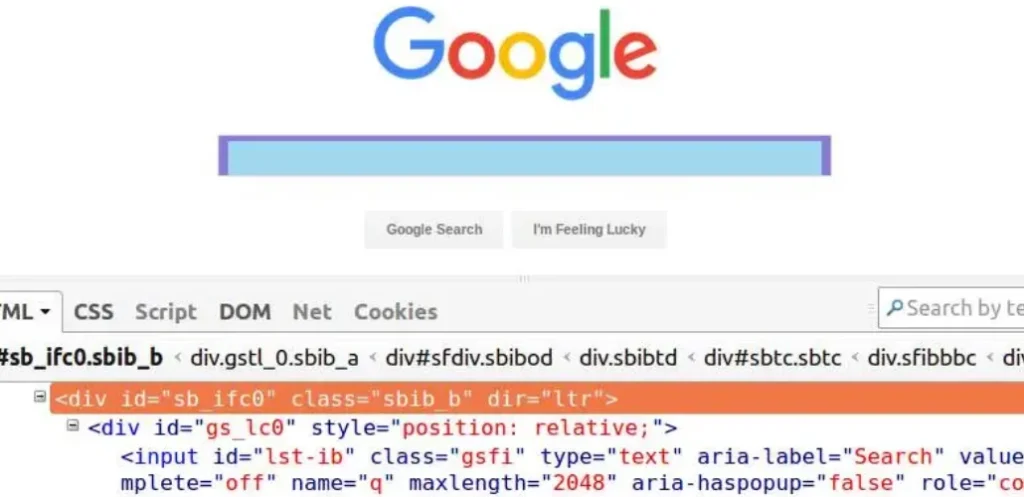
- ‚/‘ oder ‚//‘ – Einfacher Schrägstrich und doppelter Schrägstrich werden verwendet, um absolute und relative XPath-Pfade zu erstellen (wird später in diesem Lehrgang erklärt). Ein einzelner Schrägstrich wird verwendet, um die Auswahl vom Wurzelknoten aus zu starten. Der doppelte Schrägstrich wird verwendet, um den aktuellen, der Auswahl entsprechenden Knoten abzurufen. Für den Moment werden wir hier ‚//‘ verwenden.
- Tag – HTML-Tags beginnen mit ‚<‚ und enden mit ‚>‘. Sie werden verwendet, um verschiedene Elemente zu umschließen und Informationen über die Verarbeitung der Elemente zu liefern. In der obigen Abbildung sind die Tags „div“ und „input“ zu sehen.
- Attribute – Attribute definieren die Eigenschaften, die HTML-Elemente haben. In der obigen Abbildung sind die Attribute des äußeren Elements div id, classes und dir.
- AttributeValue – Attributwerte sind, wie der Name schon sagt, Attributwerte, z. B. „sb_ifc0“ ist der Wert des Attributs „id“.
Mit der oben gezeigten XPath-Syntax können wir mehrere XPath-Ausdrücke für das in der Abbildung gezeigte Google searchbar-div erstellen, z. B. //div[@id=’sb_ifc0′], //div[@class=’sbib_b‘] oder //div[@dir=’ltr‘]. Jeder dieser Ausdrücke kann verwendet werden, um das gewünschte Element abzurufen, solange die ausgewählten Attribute eindeutig sind.
Was sind die verschiedenen Arten von XPath?
Es gibt zwei Arten von XPath-Ausdrücken:
- Absoluter XPath – XPath-Ausdrücke, die mit absoluten XPath-Ausdrücken erstellt werden, beginnen die Auswahl beim Wurzelknoten. Diese Ausdrücke beginnen entweder mit einem „/“-Zeichen oder einem Wurzelknoten und durchlaufen das gesamte DOM, um das Element zu finden.
- Relativer XPath – Relative XPath-Ausdrücke sind viel kompakter und verwenden führende doppelte Schrägstriche ‚//‘. Diese XPath-Ausdrücke können Elemente an jeder Stelle auswählen, die den Auswahlkriterien entspricht und nicht unbedingt mit dem Wurzelknoten beginnt.
Welcher dieser beiden Ausdrücke ist also besser?“ – Relative XPath-Ausdrücke werden als besser angesehen, weil sie einfacher zu lesen und zu erstellen sind und außerdem robuster sind. Das Problem bei absoluten XPath-Pfaden ist, dass selbst eine kleine Änderung im DOM vom Pfad des Wurzelknotens zum gewünschten Element den XPath-Pfad ungültig machen kann.
Suche nach dynamischen Elementen mit XPaths
In der Automatisierung haben wir oft entweder keine eindeutigen Attribute von Elementen, die sie eindeutig identifizieren, oder die Elemente werden dynamisch erzeugt, wobei der Wert des Attributs nicht im Voraus bekannt ist.
Für solche Fälle bietet XPath verschiedene Methoden für die Suche nach Elementen, z. B. durch Verwendung des Textes, der über den Elementen steht, durch Verwendung des Index des Elements, durch Verwendung eines teilweise übereinstimmenden Attributwerts, durch Verschieben zu einem Geschwister-, Kind- oder Elternteil des Elements, das eindeutig identifiziert werden kann, und so weiter.
Verwendung der Funktion text()
Mit der Funktion text() können wir ein Element anhand des darüber geschriebenen Textes finden, z. B. XPath für die Schaltfläche „GoogleSearch“:
//*[text()=’Google Search‘] (hier haben wir ‚*‘ verwendet, um jedes Tag mit dem gewünschten Text abzugleichen)
Verwendung der Funktion contains()
Mit der Funktion contains() können wir auch die Werte von teilweise identischen Attributen vergleichen. Dies ist besonders nützlich bei der Suche nach dynamischen Werten, von denen ein Teil konstant bleibt, z. B. Der XPath für das äußere Div im obigen Bild mit der ID „sb_ifc0“ kann auch mit der partiellen ID „sb“ unter Verwendung von contains() gefunden werden – //div[contains(@id,’sb‘)]
Verwendung des Elementindexes
Durch Angabe der Indexposition in eckigen Klammern können wir zum n-ten Element gehen, das die Bedingung erfüllt, z. B. //div[@id=’elementid‘]/input[4] ruft das vierte Eingabeelement innerhalb des div-Elements ab.
XPath-Achsen verwenden
XPath-Achsen helfen bei der Lokalisierung komplexer Webelemente, indem sie über ein Geschwister-, Nachkommen- oder übergeordnetes Element von anderen Elementen, die leicht identifiziert werden können, geleitet werden. Einige der am häufigsten verwendeten Achsen sind:
| Kind | Auswahl von Unterknoten des Referenzknotens. Syntax – XpathForReferenceNode/child::tag |
| Elternteil | Auswahl des übergeordneten Knotens des Referenzknotens. Syntax – XpathForReferenceNode/parent::tag |
| unter | Markieren Sie alle Knoten, die auf den Referenzknoten folgen. Syntax – XpathForReferenceNode/following::tag |
| vorhergehende | Markieren Sie alle Knoten, die vor dem Referenzknoten liegen. Syntax – XpathForReferenceNode/preceding::tag |
| Vorfahren | Auswahl aller Vorgängerelemente vor dem Referenzknoten. Syntax – XpathForReferenceNode/ancestor::tag |


