
Tutorial XPath en Selenium y otras herramientas automatizadas

 MIN
MIN
 01 Dic 2023
01 Dic 2023
En este tutorial de xPath, cubriremos el uso del localizador XPath en Selenium WebDriver y otras herramientas automatizadas. En nuestro post sobre cómo encontrar WebElements en Selenium, estudiamos los distintos tipos de localizadores utilizados en Selenium WebDriver.
Aquí estudiaremos cómo crear localizadores Xpath, los distintos tipos de Xpath y cómo buscar elementos dinámicos utilizando XPath.
Índice
¿Qué es XPath?
XPath puede definirse como un lenguaje de consulta utilizado para navegar por documentos XML con el fin de encontrar diversos elementos. La sintaxis básica de la expresión XPath es-.
//tag[@attributeName=’attributeValues’]
Utilicemos ahora un ejemplo para comprender los distintos elementos de la sintaxis de la expresión Xpath: etiquetas, atributos y valores de atributos. Considera la siguiente imagen de una página web de Google con Firebug controlando el div de la Barra de Búsqueda.
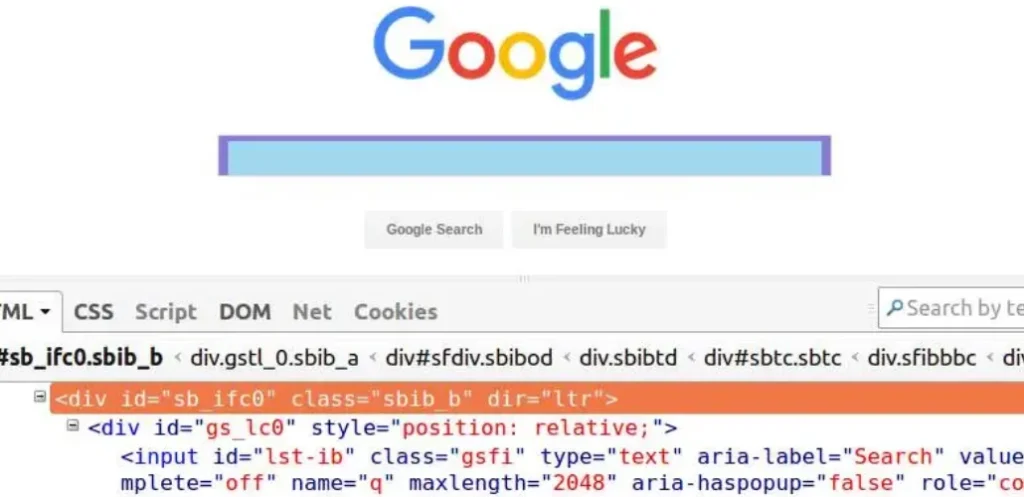
- ‘/’ o ‘//’ – La barra oblicua simple y la barra oblicua doble se utilizan para crear rutas XPath absolutas y relativas (se explican más adelante en este tutorial). Se utiliza una sola barra para iniciar la selección desde el nodo raíz. Mientras que la doble barra se utiliza para recuperar el nodo actual correspondiente a la selección. Por ahora, utilizaremos aquí «//».
- <>Etiqueta – Las etiquetas HTML empiezan por ‘ ‘ y terminan por ‘ ‘. Se utilizan para encerrar diferentes elementos y proporcionan información sobre el tratamiento de los elementos. En la imagen anterior, se muestran las etiquetas ‘div’ y ‘input’.
- Atributo – Los atributos definen las propiedades que tienen los elementos HTML. En la figura anterior, los atributos div del elemento exterior son id, classes y dir.
- AttributeValue – Los valores de atributo, como su nombre indica, son valores de atributo, por ejemplo «sb_ifc0» es el valor del atributo «id».
Utilizando la sintaxis XPath mostrada anteriormente, podemos crear varias expresiones XPath para la barra de búsqueda-div de Google mostrada en la imagen, como //div[@id=’sb_ifc0′], //div[@class=’sbib_b’], o //div[@dir=’ltr’]. Cualquiera de estas expresiones puede utilizarse para recuperar el elemento deseado, siempre que los atributos seleccionados sean únicos.
¿Cuáles son los distintos tipos de XPath?
Existen dos tipos de expresiones XPath:
- XPath absoluto – Las expresiones XPath creadas utilizando expresiones XPath absolutas inician la selección desde el nodo raíz. Estas expresiones empiezan con un carácter «/» o un nodo raíz y recorren todo el DOM para llegar al elemento.
- XPath relativo – Las expresiones XPath relativas son mucho más compactas y utilizan dobles barras inclinadas iniciales ‘//’. Estas expresiones XPath pueden seleccionar elementos en cualquier lugar que coincida con los criterios de selección y no empiece necesariamente por el nodo raíz.
Entonces, ¿cuál de estas dos expresiones es mejor?» – Las expresiones XPath relativas se consideran mejores porque son más fáciles de leer y crear, y también son más robustas. El problema de las rutas XPath absolutas es que incluso un pequeño cambio en el DOM de la ruta del nodo raíz al elemento deseado puede invalidar la ruta XPath.
Buscar elementos dinámicos mediante XPaths
En automatización, muchas veces o bien no tenemos atributos únicos de los elementos que los identifiquen unívocamente, o bien los elementos se generan dinámicamente, sin que se conozca de antemano el valor del atributo.
Para estos casos, XPath proporciona varios métodos de búsqueda de elementos, por ejemplo: utilizando el texto escrito encima de los elementos; utilizando el índice del elemento; utilizando un valor de atributo que coincida parcialmente; desplazándose a un hermano, hijo o padre del elemento que pueda identificarse unívocamente, etc.
Utilizar la función text()
Utilizando la función text() podemos encontrar un elemento basándonos en el texto escrito sobre él, por ejemplo XPath para el botón «GoogleBuscar»:
[text()=’Google Search’]//* (aquí utilizamos «*» para que coincida cualquier etiqueta con el texto deseado)
Utilizar la función contains()
Utilizando la función contains(), también podemos comparar los valores de atributos parcialmente idénticos. Esto es especialmente útil cuando se buscan valores dinámicos, parte de los cuales permanecen constantes, por ejemplo El XPath para el div exterior de la imagen anterior con id «sb_ifc0» también se puede encontrar con id parcial – «sb» utilizando contains() – //div[contains(@id,’sb’)]
Uso del índice de elementos
Especificando la posición del índice entre corchetes, podemos desplazarnos al enésimo elemento que cumpla la condición, por ejemplo //div[@id=’elementid’]/input[4 ] recupera el cuarto elemento de entrada dentro del elemento div.
Utilizar ejes XPath
Los ejes XPath ayudan a localizar elementos web complejos haciéndolos pasar por hermanos, descendientes o padres de otros elementos que pueden identificarse fácilmente. Algunos de los ejes más utilizados son
| niño | Selección de nodos hijos del nodo de referencia. Sintaxis – XpathForReferenceNode/child::tag |
| padre | Selección del nodo padre del nodo de referencia. Sintaxis – XpathForReferenceNode/parent::tag |
| siguiendo | Selecciona todos los nodos que siguen al nodo de referencia. Sintaxis – XpathForReferenceNode/following::tag |
| precedente | Selecciona todos los nodos que están antes del nodo de referencia. Sintaxis – XpathForReferenceNode/preceding::tag |
| antepasado | Selección de todos los elementos antecesores anteriores al nodo de referencia. Sintaxis – XpathForReferenceNode/ancestor::tag |


