
Tutoriál XPath v Selenium a iných automatizovaných nástrojoch

 3 MIN
3 MIN
 01 dec 2023
01 dec 2023
V tomto tutoriáli xPath sa budeme venovať použitiu lokátora XPath v Selenium WebDriver a iných automatizovaných nástrojoch. V našom príspevku o hľadaní WebElements v Selenium sme študovali rôzne typy lokátorov používaných v Selenium WebDriver.
Tu budeme študovať spôsob vytvárania lokátorov Xpath, rôzne typy Xpath a spôsoby vyhľadávania dynamických prvkov pomocou XPath.
Obsah
Čo je to XPath?
XPath možno definovať ako dotazovací jazyk používaný na navigáciu v dokumentoch XML s cieľom nájsť rôzne prvky. Základná syntax výrazu XPath je-
//tag[@attributeName=’attributeValues‘]
Poďme teraz na príklade pochopiť jednotlivé prvky syntaxe výrazu Xpath – značky, atribúty a hodnoty atribútov. Uvažujme nasledujúci obrázok webovej stránky Google s programom Firebug, ktorý kontroluje div Search-bar.
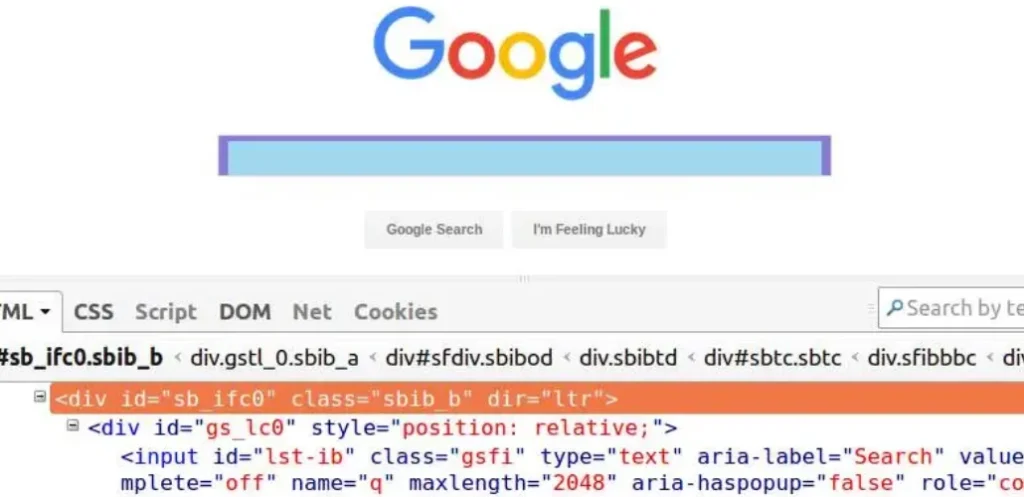
- ‚/‘ alebo ‚//‘ – Jednoduché lomítko a dvojité lomítko sa používajú na vytváranie absolútnych a relatívnych ciest XPath (vysvetlené neskôr v tomto návode). Jednoduché lomítko sa používa na začatie výberu od koreňového uzla. Zatiaľ čo dvojité lomítko sa používa na načítanie aktuálneho uzla zodpovedajúceho výberu. Zatiaľ tu budeme používať ‚//‘.
- Tag – Značky v jazyku HTML začínajú znakom ‚<‚ a končia znakom ‚>‘. Používajú sa na uzavretie rôznych prvkov a poskytujú informácie o spracovaní prvkov. Na vyššie uvedenom obrázku sú značky ‚div‘ a ‚input‘.
- Atributte – Atribúty definujú vlastnosti, ktoré majú prvky HTML. Na vyššie uvedenom obrázku sú atribútmi vonkajšieho elementu div id, classes a dir.
- AttributeValue – Hodnoty atribútov, ako naznačuje názov, sú hodnoty atribútov, napr. „sb_ifc0“ je hodnota atribútu „id“.
Pomocou vyššie zobrazenej syntaxe XPath môžeme vytvoriť viacero výrazov XPath pre Google searchbar-div uvedený na obrázku, ako napríklad //div[@id=’sb_ifc0′], //div[@class=’sbib_b‘] alebo //div[@dir=’ltr‘]. Na načítanie požadovaného prvku možno použiť ktorýkoľvek z týchto výrazov, pokiaľ sú zvolené atribúty jedinečné.
Aké sú rôzne typy XPath?
Existujú dva druhy výrazov XPath:
- Absolútny XPath – Výrazy XPath vytvorené pomocou absolútnych výrazov XPath začínajú výber od koreňového uzla. Tieto výrazy začínajú buď znakom „/“, alebo koreňovým uzlom (root node) a prechádzajú celým DOM, aby sa dostali k prvku.
- Relatívny XPath – Relatívne výrazy XPath sú oveľa kompaktnejšie a používajú predné dvojité lomítka ‚//‘. Tieto výrazy XPath môžu vyberať prvky na ľubovoľnom mieste, ktoré zodpovedá kritériám výberu a nemusí nevyhnutne začínať koreňovým uzlom.
Ktorý z týchto dvoch výrazov je teda lepší?“ – Relatívne výrazy XPath sa považujú za lepšie, pretože tieto výrazy sa ľahšie čítajú a vytvárajú; a tiež sú robustnejšie. Problém s absolútnymi cestami XPath je, že aj malá zmena v DOM od cesty koreňového uzla k požadovanému prvku môže spôsobiť neplatnosť cesty XPath.
Vyhľadávanie dynamických prvkov pomocou XPaths
V automatizácii mnohokrát buď nemáme k dispozícii jedinečné atribúty prvkov, ktoré ich jednoznačne identifikujú, alebo sú prvky dynamicky generované, pričom hodnota atribútu nie je vopred známa.
Pre takéto prípady poskytuje XPath rôzne metódy vyhľadávania prvkov, napríklad – pomocou textu napísaného nad prvkami; pomocou indexu prvku; pomocou čiastočne zhodnej hodnoty atribútu; presunom na súrodenca, potomka alebo rodiča prvku, ktorý možno jednoznačne identifikovať a podobne.
Použitie funkcie text()
Pomocou funkcie text() môžeme nájsť prvok na základe textu napísaného nad ním, napr. XPath pre tlačidlo „GoogleSearch“:
//*[text()=’Google Search‘] (tu sme použili ‚*‘ na porovnanie akéhokoľvek tagu s požadovaným textom)
Použitie funkcie contains()
Pomocou funkcie contains() môžeme porovnať aj hodnoty čiastočne zhodných atribútov. To je užitočné najmä pri vyhľadávaní dynamických hodnôt, ktorých časť zostáva konštantná, napr. XPath pre vonkajší div na vyššie uvedenom obrázku s id „sb_ifc0“ možno nájsť aj s čiastočným id – „sb“ pomocou contains() – //div[contains(@id,’sb‘)]
Použitie indexu prvku
Zadaním pozície indexu v hranatých zátvorkách sa môžeme presunúť na n-ty prvok spĺňajúci podmienku, napr. //div[@id=’elementid‘]/input[4] načíta štvrtý vstupný prvok vo vnútri prvku div.
Používanie osí XPath
Osy XPath pomáhajú pri vyhľadávaní zložitých webových prvkov ich prechádzaním cez súrodenca, potomka alebo rodiča iných prvkov, ktoré možno ľahko identifikovať. Niektoré zo široko používaných osí sú:
| child | Výber podriadených uzlov referenčného uzla. Syntax – XpathForReferenceNode/child::tag |
| parent | Výber nadradeného uzla referenčného uzla. Syntax – XpathForReferenceNode/parent::tag |
| following | Výber všetkých uzlov, ktoré nasledujú za referenčným uzlom. Syntax – XpathForReferenceNode/following::tag |
| preceding | Výber všetkých uzlov, ktoré sa nachádzajú pred referenčným uzlom. Syntax – XpathForReferenceNode/preceding::tag |
| ancestor | Výber všetkých prvkov predkov pred referenčným uzlom. Syntax – XpathForReferenceNode/ancestor::tag |


